Posts filed under 'Lehrstück'

… und wenn wir schon bei Veranstaltungshinweisen sind, gebe ich auch noch einen: Am kommenden Sonntag, dem 19. November, findet in der BMW-Niederlassung Saarbrücken eine sog. Wissenschaftsmatinee statt. Das ist eine Veranstaltungsreihe, in der verschiedene wissenschaftliche Bereiche für Nicht-Fachpublikum vorgestellt werden.
Diesen Sonntag redet Prof. Dr. Manfred Pinkal über Computerlinguistik: “Mit technischen Geräten reden – Natürlicher Sprachdialog im Fahrzeug”. Eine vorherige Anmeldung ist erwünscht.
Das Ganze ist eine Veranstaltungsreihe des Wissenschaftforums Saar, die Einladung zur Matinee am Sonntag gibt es als PDF (und sieht meiner bescheidenen Meinung nach viel cooler aus als die Wissenschaftsforums-Homepage).
November 16th, 2006 05:18pm
Kategorie: Lehrstück

Ich werde über meine und andere Arbeiten im Bereich der Musikempfehlungsmaschinen sprechen. Tag der Informatik bedeutet natürlich fachfremdes Publikum. Nachwuchs, den es zu begeistern gilt. Natürlich gebe ich alles und habe zum Glück ein sehr dankbares Thema: Amazon, Pandora, Last.fm, MPEER, BluetunA, etc.
Dies sagt die Pressemitteilung:
Tag der offenen Tür im DFKI-KL, 17.11.06
“Am 17. November findet in Kaiserslautern im Rahmen des “Informatikjahrs 2006″ eine Gemeinschaftsveranstaltung mit Workshops, Systemdemonstrationen und Vorträgen statt. Der Titel der Veranstaltung lautet “Informatik – Motor der Zukunft: IT-Welten zum Entdecken, Verweilen und Diskutieren”. Unter diesem Motto präsentieren sich die Fraunhofer-Institute IESE und ITWM, die Informatik-Fachbereiche der TU und der FH Kaiserslautern, die GI-Regionalgruppe Saar-Pfalz und das Deutsche Forschungszentrums für Künstliche Intelligenz (DFKI). Die interessierte Öffentlichkeit ist herzlich eingeladen an der Veranstaltung teilzunehmen. Das DFKI stellt in der Rotunde (Gebäude 57, Campus der TU Kaiserslautern) und Im Foyer des Gebäudes 48 spannende Projekte aus den Bereichen Wissensmanagement, Intelligente Visualisierung und Simulation, Bildverstehen und Mustererkennung, Intelligente Benutzerschnittstellen, Sprachtechnologie und Computational Culture vor.”
November 15th, 2006 02:49pm
Kategorie: Auf Tour, Lehrstück, Präsentation 2.0
heute: Warum der Ansatz vom letzten Mal eine Sackgasse ist
Letztes Mal habe ich versucht zu erklären, wie Sätze im Prinzip syntaktisch analysiert werden können. Diese Analyse nennt sich Parsing und lässt sich auch umdrehen, was dann Generierung heißt.
Sprich: Mit einer Grammatikdefinition (S -> NP V etc.) kann man einen echten Satz (wie “Die Frau schläft”) auf ein abstrakte Repräsentation des Satzes zurückführen (wie “S”) oder eine abstrakte Repräsentation auf einen Satz.
Es gibt computerlinguistische Anwendungen, für die das reicht. Und deswegen werden wir das noch etwas vertiefen.
Schon beim letzten Mal sind wir über ein Problem gestolpert, das sich Agreement nennt. In einer Nominalphrase (normalerweise ein Artikel und ein Nomen, evtl. dazwischen noch Adjektive) z.B. müssen die Konstituenten in Kasus (Fall), Numerus (Singular vs. Plural) und Genus (männlich, weiblich, sächlich) übereinstimmen. *der groß katzen ist einfach nicht korrekt. Korrekt wäre die großen katzen oder der große kater oder …
Unsere Grammatik muss das berücksichtigen. Deswegen reichen die die beiden Regeln für NPs vom letzten Mal nicht aus. Damals hatten wir
NP -> D_fem N_fem
NP -> D_mas N_mas
festgelegt. Das muss erweitert werden:
NP_fem_nom_sg -> D_fem_nom_sg N_fem_nom_sg
NP_mas_nom_sg -> D_mas_nom_sg N_mas_nom_sg
NP_neu_nom_sg -> D_neu_nom_sg N_neu_nom_sg
NP_fem_nom_pl -> D_fem_nom_pl N_fem_nom_pl
NP_mas_nom_pl -> D_mas_nom_pl N_mas_nom_pl
NP_neu_nom_pl -> D_neu_nom_pl N_neu_nom_pl
Wir sehen schon, dass die Angelegenheit dadurch nicht schöner wird. Noch unschöner wird es, wenn wir berücksichtigen, dass es auch zwischen Subjekt und Verb eine Übereinstimmung in Person und Numerus geben muss: *die frau schlafen ist genau deswegen falsch. Unsere S -> NP V-Regel müsste also abgewandelt werden:
S -> NP_3_sg V_3_sg
S -> NP_3_pl V_3_pl
Und an dieser Stelle brechen wir das Experiment ab, weil mittlerweile klar sein sollte, dass ein derart gebautes System praktisch unmöglich zu warten oder zu überblicken ist (zudem gibt es Zweifel, ob es theoretisch möglich ist). Denn zusätzlich zu der einfach Subjekt-Verb-Übereinstimmung gibt komplexere Beziehungen, die die Zahl der Regeln jedesmal enorm aufbläht.
Was man stattdessen macht: Man parametrisiert die Regeln[1]. Konkret: Statt unzähliger Regeln wie oben definieren wir nur noch eine einzige:
NP(?gen, ?kas, ?num) -> D(?gen, ?kas, ?num) N(?gen, ?kas, ?num)
Diese Regel würde dem Grammatiksystem sagen, dass, wenn immer es einen Artikel und ein Nomen zu einer NP zusammenwirft, Genus, Kasus und Numerus übereinstimmen müssen (Nicht-Informatiker können sich das als Textersetzungen vorstellen, wobei die mit ? markierten Variablen jeweils übereinstimmen müssen).
Die Satz-Regel würde dann so aussehen:
S(3,?num) -> NP(?_, nom, ?num) V(3, ?num)
In diesem Fall zeigt ?_, dass wir alles erlauben, während ‘nom’ bereits festgelegt ist. Auch erlauben wir Verben nur in der dritten Person, weil Nominalphrasen in der dritten Person sind. Für Sätze wie “Ich schlafe” brauchen wir Pronomen, die unser Lexikon derzeit noch nicht enthält. A propos: Das Lexikon:
V(3, sg) -> schläft
V(3, pl) -> schlafen
D(mas, nom, sg) -> der
D(fem, nom, sg) -> die
D(?_, nom, pl) -> die
N(fem, nom, sg) -> frau
N(fem, nom, pl) -> frauen
N(mas, nom, sg) -> mann
N(mas, nom, pl) -> männer
Damit erkennt unsere Grammatik die folgenden Sätze:
- die frau schläft
- die frau schlafen
- der mann schläft
- die männer schlafen
Der Satz “die frauen schlafen” sieht dann z.B. so aus:

Mit diesen Zutaten können wir eine einfache Grammatikprüfung programmieren, wie sie in einigen Schreibprogrammen Anwendung findet. Für komplexere (und spannendere) Anwendungen der Computerlinguistik brauchen wir natürlich mehr Informationen, als dass “die frau schläft” ein Satz ist. Und dazu kommen wir beim nächsten Mal (auch weil mich die ganzen schlafenden Leute müde gemacht haben …).
Anmerkungen
[1]: Das ist eine Vereinfachung. Grammatiktheorien wie HPSG oder LFG sind natürlich nicht bloß parametrisierte kontextfreie Grammatiken. Aber ich tue jetzt mal so als ob.
October 28th, 2006 01:18pm
Kategorie: Lehrstück

Per freundlicher Email-Anfrage wurde ich gebeten, ein wenig Blogpromotion für den Film Weizenbaum. Rebel at Work zu machen. Ein kleines Posting gibt es drüben beim C4. Die Website der Filmmacher enthält einiges an Material jedweder Mediengattung zum Download, Stream, etc. Da auch ich bereits Gelegenheit hatte mit Weizenbaum zu sprechen, kann ich jedem nur empfehlen, sich mit dieser interessanten Persönlichkeit auseinanderzusetzen. Viel Freude mit dem Material!
October 20th, 2006 02:54pm
Kategorie: Fundsachen, Lehrstück
heute: Syntax und Morphologie
Syntax und Morphologie werden in der Computerlinguistik oft in einem Atemzug genannt, weil es ähnliche Konzepte sind, die beiden Disziplinen zugrundeliegen. Insofern ist die Grenze etwas vage. Morphologie beschäftigt sich mit der Bildung von Wörtern und Syntax mit der Bildung von Sätzen. (Wohlgeformte) Sätze (bzw. Wörter) sind ja normalerweise keine bloße Ansammlung von Wörtern (bzw. Zeichen), sondern erfordern eine bestimmte Struktur – das alles haben wir in der Schule unter dem Begriff “Grammatik” mal gelernt.
2.4 In der Zeitung steht, dass der Lieferant von Gammelfleisch erst gestern erfuhr.
Diesen Satz kennen wir vom letzten Mal. Seine Mehrdeutigkeit kann am Ende aufgelöst werden, weil das Verb “erfahren” (die Abbildung von “erfuhr” [Präteritum] auf die Zitierform ist übrigens Teil der morphologischen Analyse) ein Objekt verlangt. Das, von dem erfahren wird. Dieses Objekt ist “Gammelfleisch”, wodurch es nicht mehr als Modifikator von “Lieferant” zur Verfügung steht.
Wie kommen wir also an solche Informationen? Mit einem Parser. Es ist leichter zu erklären was ein Parser in der Computerlinguistik tun muss, wenn man die Perspektive wechselt. Stellen wir uns vor, wir wollen ein Programm schreibt, dass anhand eines gegebenen Lexikons alle möglichen syntaktisch korrekten deutschen Sätze generiert. Nehmen wir zum Beispiel folgendes Lexikon an, in dem zu jedem Eintrag die Wortart (N=Nomen, D=Artikel, V=Verb) steht:
N -> frau
N -> katze
D -> der
D -> die
V -> schläft
Nun brauchen wir noch die Grammatikspezifikation, die uns sagt, dass die katze schläft gut ist, * katze frau der die schläft aber nicht.
Eine grundlegende Konstruktion in den allermeisten Sprachen ist die von Artikel und Nomen. Deswegen definieren wir, dass ein Artikel gefolgt von einem Nomen zusammen eine gute Sache sind – und zusammen eine Nominalphrase (NP) ergeben:
NP -> D N
Da wir damit noch keinen Satz haben, erlauben wir außerdem die Kombination von einer NP gefolgt von einem Verb zu einem Satz (S):
S -> NP V
So, nun überlegen wir, was wir damit machen können. Wir wollen einen Satz (S) generieren, also fangen wir damit an. Wir haben keine andere Möglichkeit, als “S” durch “NP V” zu ersetzen, was wir tun. Im nächsten Schritt ersetzen wir “V” durch “schläft” und “NP” durch “D N”. Jetzt sind wir ungefähr hier:
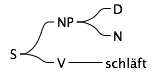
Ab hier bauen wir mehr als einen Satz, weil wir die Wahl zwischen mehreren (insgesamt 4) Alternativen haben. Heraus kommen also die folgenden vier Sätze:
- der frau schläft
- der katze schläft
- die frau schläft
- die katze schläft
(Wer sich wundert, dass ihm das alles bekannt vorkommt: Ja, das ist nichts spezifisch computerlinguistisches. Es handelt sich um eine kontextfreie Grammatik)
Jetzt haben wir vier Sätze generiert, von denen 2 grammatikalisch falsch sind. Das ist ja nicht so super. Dem können wir aber abhelfen, indem wir die Regel für Nominalphrasen und das Lexikon verändern.
Was schiefläuft, ist, dass das grammatikalische Geschlecht von “frau” und “der” nicht übereinstimmt (und “katze” und “der”). Die Information darüber muss also erstmal ins Lexikon:
N_fem -> frau
N_fem -> katze
D_mas -> der
D_fem -> die
V -> schläft
Und die Regel für NPs muss natürlich entsprechend angepasst werden:
NP -> D_fem N_fem
NP -> D_mas N_mas
Das war’s. Jetzt bekommen wir nur noch zwei Sätze, die beide grammatikalisch korrekt sind:
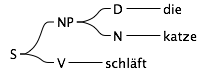
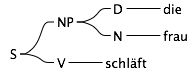
Wir haben jetzt dafür gesorgt, dass es innerhalb einer Nominalphrase nur noch ein grammatikalisches Geschlecht gibt. Der Computerlinguist bezeichnet das auch gerne als “Agreement”, also als Übereinstimmung.
Und nächstes Mal erkläre ich, wie wir damit Sätze wie 2.4 eindeutig machen können.
October 16th, 2006 10:47am
Kategorie: Lehrstück
heute: Mehrdeutigkeiten in natürlicher Sprache
Mehrdeutigkeiten – also Wörter, Satzteile oder Satzstrukturen, die mehr als eine Bedeutung haben können – sind ein echtes Problem für alle, die natürliche Sprache verarbeiten wollen. Denn Mehrdeutigkeiten treten nicht nur, wie beim letzten Mal gesehen, in verstümmelten Sätzen oder Stichworten auf. Ganze Sätze können, obwohl sie grammatikalisch wunderbares Deutsch sind, mehrere Bedeutungen haben.
1. Der Senat plant offenbar noch in der kommenden Woche eine Gesetzesinitiative gegen Kampfhunde im Abgeordnetenhaus.
[1]
Dieser Satz ist mehrdeutig, auch wenn wir das allenfalls humoristisch wahrnehmen (das langweilige Lehrbuchbeispiel für diese Art Mehrdeutigkeit ist Der Mann sieht den Jungen mit dem Fernglas
). Die Mehrdeutigkeit besteht natürlich darin, dass wir nicht wissen, ob die Gesetzesinitiative sich gegen Kampfhunde im Abgeordnetenhaus richtet oder ob sich die Initiative im Abgeordnetenhaus gegen Kampfhunde richtet.
2. Die Gießkannen kaufe ich dir nicht ab.
3. Die Geschichte kaufe ich dir nicht ab.
Sätze 2 und 3 sind insgesamt freilich nicht mehrdeutig, aber wir sehen schon, dass “kaufe” hier mit völlig unterschiedlichen Bedeutungen benutzt wird. Insofern ist “abkaufen” ohne Kontext ebenfalls mehrdeutig.
4. In der Zeitung steht, dass der Lieferant von Gammelfleisch erst gestern erfuhr.
Der ein oder andere Leser mag über sen Satz gestolpert sein, zwischendurch ist er nämlich ebenfalls mehrdeutig. “Lieferant von XY” ist eine sehr häufig vorkommende Wendung, so dass Menschen, wenn sie den Satz lesen, erst denken, dass der Lieferant eben Gammelfleisch geliefert hätte. Am Ende des Satzes lesen wir “erfuhr” und stellen fest, dass “von Gammelfleisch” zu “erfuhr” gehören muss, und interpretieren den Satz neu.
Nach diesen paar Beispielen – wenn man darauf achtet, findet man auf jeder Zeitungsseite weitere – sollte klar sein, dass Mehrdeutigkeiten häufig vorkommen und dass sie auf verschiedenen Ebenen auftreten. Die Mehrdeutigkeit in z. B. 2./3. ist eine ganz andere, als die in 1.
Der Linguist spricht in 2./3. von lexikalischen Mehrdeutigkeiten, weil es eine Frage des Lexikons der Sprache ist. Im Zuge unseres Sprachlernens haben wir gelernt, dass “abkaufen” in unterschiedlichen Bedeutungen genutzt werden kann. Denkt man eine Weile darüber nach, lassen sich für die meisten Wörter alternative Lesarten finden: Menü, Depot, atmen, geben, Führer, Test, Bombe, …
Die Mehrdeutigkeit in 4. ist im Grunde die gleiche wie in 1., mit dem Unterschied, dass sie in 4. noch innerhalb des Satzes aufgelöst wird und in 1. nicht. Im Satz 4 muss ich nichts über Gammelfleisch, Lieferanten oder Zeitungen wissen, um die Mehrdeutigkeit aufzulösen, es reicht zu wissen, dass das Verb “erfahren” immer etwas braucht, wovon erfahren wird (Ich erfahre von dem Skandal.
ist ein korrekter Satz, *Ich erfahre.
dagegen nicht[2]). Es handelt sich demgemäß um eine syntaktische Mehrdeutigkeit, weil sie auf Ebene der Syntax (vulgo: der Grammatik) auftritt. In Satz 1 reicht Wissen über Grammatik nicht aus, um den Satz eindeutig zu machen. Ohne Wissen über Abgeordnete, Kampfhunde und so weiter (sog. Weltwissen), kommt man da nicht weiter. Die Mehrdeutigkeit des Satzes lässt sich nur auf der Ebene der Bedeutung, des eigentlichen Inhaltes (Semantik) des Satzes auflösen.
Und weil ich Syntax jetzt schon angerissen habe, wird es darum beim nächsten Mal gehen. Wie zerlege ich Sätze in syntaktische Strukturen? Was macht eine Grammatikprüfung, bzw. was sollte sie machen?
Anmerkungen
[1]: Der Tagesspiegel vom 5. Juli 2000
[2]: In linguistischer Literatur werden ungrammatikalische Sätze mit Sternchen gekennzeichnet, damit es keine Verwirrung gibt. Ich behalte das hier mal bei, weil ich denke, dass es hilfreich ist.
October 7th, 2006 08:25pm
Kategorie: Lehrstück
Nehmen wir an, wir suchen Informationen im Internet, etwa über den Verkauf von Chrysler an Daimler. Das ist kein großes Problem, wir suchen nach verkauf chrysler daimler. Google liefert uns dafür nicht weniger als 465.000 Suchergebnisse, viele davon möchten Autos oder Aktien verkaufen, etwas wie einen Zeitungsartikel über den Verkauf selbst finden wir nicht – zumindest nicht auf den ersten paar Seiten, die für einen Menschen noch erfassbar sind.
Bohlen verlegt Haus könnte eine Überschrift von “Bild” sein. Wir möchten mehr darüber wissen, suchen danach – und finden reihenweise Tipps für Heimwerker, wie man Bohlen in seinem Haus verlegt.
Sicher, beide Beispiele sind zu einem gewissen Maß konstruiert und lassen sich durch Umformulierung und / oder dem Hinzufügen weiterer Stichworte reparieren – ich würde einfach mal wetten, dass jede Leserin und jeder Leser schon des Öfteren Zeit damit vergeudetbraucht hat, die richtige Kombination von Suchbegriffen zu finden.

(photo by nofrills)
Das Problem ist aber eigentlich ein grundsätzliches und hat vor allem damit zu tun, wie wir Menschen Sprache benutzen und wie schwierig das für einen Computer ist. Genau damit beschäftigt sich das Fach “Computerlinguistik” / “Sprachtechnologie”: Mit der Frage, was man alles wissen und tun muss, um Computer in die Lage zu versetzen Sprache so zu verarbeiten und zu produzieren wie Menschen das tun.
Da das das nächste große “Ding” im Bereich Mensch-Maschine-Schnittstelle Sprache sein dürfte (und weil ich es super-interessant finde) möchte ich hier versuchen, in einer kleinen Serie einen Einblick zu geben, mit welchen Problemen man sich als Computerlinguist so herumschlägt und welche Lösungen und Lösungsansätze dafür existieren. Diese Einführung richtet sich dabei ausdrücklich an alle – Fragen und Feedback sind mir herzlich willkommen (auch weil ich zum ersten Mal systematisch versuche, mein Fach zu erklären ;-) ).
Zum Einstieg: Warum gehen die oben skizzierten Beispiele so schief? Im ersten Beispiel fehlt der Suchabfrage die Information, wer wem was verkauft hat. Was wir da bräuchten, wäre eine Angabe, die besagt, dass Daimler der Käufer ist und Chrysler das gekaufte. Dann könnte Google im Internet nach genau dieser Rollenverteilung suchen. Es könnte ja auch genau andersherum sein oder so dass “Chrysler” und “Daimler” nicht als Firmen gemeint sind sondern als Autos der Marke und eben beide verkauft werden.
Im zweiten Beispiel wissen wir ebenfalls nichts über die Rollenverteilung. Dazu kommt aber noch, dass sowohl “Bohlen” als auch “verlegt” mehrdeutig sind. “Bohlen” können eben Holzbohlen oder ein Eigenname sein, “verlegt” kann im Sinne von “Wohnsitz verlegen” oder “Boden verlegen” gebraucht werden.
Für bessere Suchergebnisse braucht man also eine linguistische Analyse, die Rollenzuweisungen vornimmt und Mehrdeutigkeiten nach Möglichkeit auflöst. Mehr Mehrdeutigkeiten gibt’s beim nächsten Mal, sie treten nämlich auf vielen unterschiedlichen Ebenen auf (und werden von Menschen normalerweise oft nichtmal bemerkt).
October 4th, 2006 02:11pm
Kategorie: Lehrstück
 Just stumbled upon supportblogging, a wiki-based resource on educational blogging. [via Christian Spannagel].
Just stumbled upon supportblogging, a wiki-based resource on educational blogging. [via Christian Spannagel].
The “B”-Button on the left is the official support-logo-button.
August 7th, 2006 09:19am
Kategorie: Fundsachen, Lehrstück
Einfach mal bei den Google-Videos nach Google engEDU suchen und ganz viele Technikvorträge anschauen.
June 20th, 2006 11:25am
Kategorie: Bloggerglück, Fundsachen, Lehrstück
Das hier ist ein Interview, was wir 2004 am DFKI via Videoconferenz durchgeführt haben. Das Interview führten Leo Sauermann und ich. Es erschien ursprünglich hier.
Ich schreibe hier grade live von einer Videokonferenz am DFKI. Wir schalten nach Wien, wo Fra Ablinger uns Einsichten in das “Schöne Scheitern” gibt. So das Motto der disjährigen Roböxotica. Die Roböxotica ist eine internationale Konferenz für Cocktail-Robotik. Gezeigt wurden verschiedene Roboter, die von Mojito-Produktion bis hin zu autonomen Ziarettenanzünderrobotern auf der Theke vielseitige einsetzbar sind. Hier in Kaiserslautern mussten die Cocktails leider manuell produziert werden: von Menschen. Als Interview Partner konnten wir Magnus Wurzer von dem Wiener Kulturasyl SHIFZ gewinnen.
HBS: “Wo kommt die Roböxitica her?”
Magnus Wurzer(SHIFZ): “Ursprung der Roböxitica war der Drang nach Befreiung der Roboter aus der Monotonie der Fabrikshallen. Wir befreien die Roboter und Stellen sie in einen kulturellen Kontext. Somit wird der Roboter auf der Roböxotica Jahr für Jahr ein wenig freier. Es geht uns also um Befreiung.”
HBS: “Was ist in diesem Jahr der Schwerpunkt?”
Magnus: “Das Thema dieses Jahr ist “schönes Scheitern”. Davon unabhängig ist essentiell, dass die Roböxitica jedes Jahr ein Treffpunkt ist, um sich auf einer gemeinsamer Ebene zu Treffen und das Thema Robotik zu diskutieren. Es gibt ein Diskursprogramm und eine sagenhafe Ausstellung. So steht eine mannigfaltige Verknüpfung von Kulturen im Mittelpunkt, denn des gibt kulturellen Austausch zwischen Menschen und Maschinen.”
HBS: “Was gibt es nächstes Jahr? Ausblick, Wünsche?”
Magnus: “Nächstes Jahr soll es viel mehr Geld geben. Es gibt so viel zu tun, was gemacht werden müsste und könnte. Deswegen muss es mehr Unterstützung geben.”
HBS: “Um welche Entwicklungen geht es?”
Magnus: “Ein Robot aus Linz konnte nicht fertigestellt werden und einer aus Frankreich auch nicht. Es muss also etwas passieren, damit die meist auch spannenden und überraschenden Einreichungen auch umgesetzt werden können!”
HBS: “Steht Wien im Zentrum der Cocktail-Robotik?”
Magnus: “Ja, das ist richtig: es gibt weltweit schon 2 oder 3 Festivals für Robotik und Kunst(in USA und Russland). Wir stehen in ständigen Diskussionen, wie man diese Festivals noch besser verzahnen kann.”
HBS: “Streams und Webcams an mehreren Punkten?
Magnus: “Könnte sein, es gab Probleme und wir arbeiten dran.”
HBS: “Roböxotica-Awards?”
Magnus: “Gibt es und wurden dieses jahr zum 6.Mal vergeben. Es gibt verschiedene Kategorien.
1. Cocktail servierende Roboter
2. Cocktailmix-Roboter
3. Konversationsroboter für Bars
4. Zigarren / Zigaretten anzündende Roboter
5. andere Höhepunkte der Cocktailkultur”
HBS: “Die meisten Roboter verrichten niedere Tätigkeiten, wie Cocktails zuzubereiten. Gib es da nicht ein ethischen Problem, wo es euch doch um die Befreiung der Roboter geht?”
Magnus: “Es geht uns nicht darum die Roboter zu einem kulturellen Produkt zu machen, sondern um eine kulturelle Annäherung. Einen Cocktail zuzubereiten ist schon eine relativ hochstehende Tätigkeit im kulturellen Umfeld. Wenn Kunden und Gäste dann auch noch Wünsche äußern, dann muss der Robot darauf reagieren. In einem kulturellen Umfeld gibt es ja auch noch wesentlich mehr als nur die Zubereitung von Cocktails, wie zum Beispiel Bar-Konversation und andere Kategorien. Daher ist die Cocktail Robotik schon ein evolutiver Schritt unter kulturellen Aspekten.”
HBS: Herzlichen Dank für das Interview!

June 13th, 2006 04:12pm
Kategorie: Auf Tour, Diskurs, Lehrstück, Präsentation 2.0
Next Posts
Previous Posts


